
AI Agents are taking enterprises by storm. Organizations are racing to build autonomous systems that reason, plan, and execute complex tasks—whether solving real problems or keeping pace with competitors.
The promise is compelling: productivity gains and capabilities that seemed impossible months ago. But beneath the excitement lies a critical challenge: How do you actually evaluate and test AI agents?
This isn’t an engineering afterthought. It’s the difference between a reliable system and an unpredictable black box that works brilliantly one moment and fails catastrophically the next. Unlike traditional software, AI agents are probabilistic and context-dependent—our old testing playbooks don’t apply.
Yet evaluation remains the unattractive, ignored piece of the puzzle. Teams prototype excitedly while pushing “How do we know this works?” to later sprints—or ignoring it entirely.
This is a mistake organizations can’t afford to make.
How are Agent Evals different from Traditional Software Testing?
Here are 5 key differences between AI Agent testing and traditional software testing:
- Non-deterministic outputs: Traditional software produces the same output for the same input every time. AI agents can generate different responses to identical prompts, making reproducible test cases nearly impossible and requiring statistical evaluation across multiple runs instead of single pass/fail checks.
- Emergent behavior and edge cases: While traditional software fails in predictable ways based on code paths, AI agents can exhibit unexpected behaviors in novel situations they weren’t explicitly trained for. The failure modes are often subtle, contextual, and impossible to enumerate in advance.
- Multi-step reasoning and chain-of-thought: Traditional tests verify individual functions or API calls. AI agents execute complex, multi-step workflows where each decision influences the next, requiring evaluation of the entire reasoning chain—not just the final output—to understand where and why things went wrong.
- Subjective quality metrics: Traditional software testing relies on objective criteria like “does this API return a 200 status code?” AI agent outputs often require human judgment to evaluate quality, relevance, tone, and appropriateness—metrics that are inherently subjective and context-dependent.
- Tool use and external interactions: Traditional software testing typically mocks external dependencies for isolation. AI agents dynamically choose which tools to use, when to use them, and how to chain them together, making it critical to test not just if they can use tools correctly, but whether they make good decisions about when and how to use them in the first place.
Building Blocks of Agent Evals
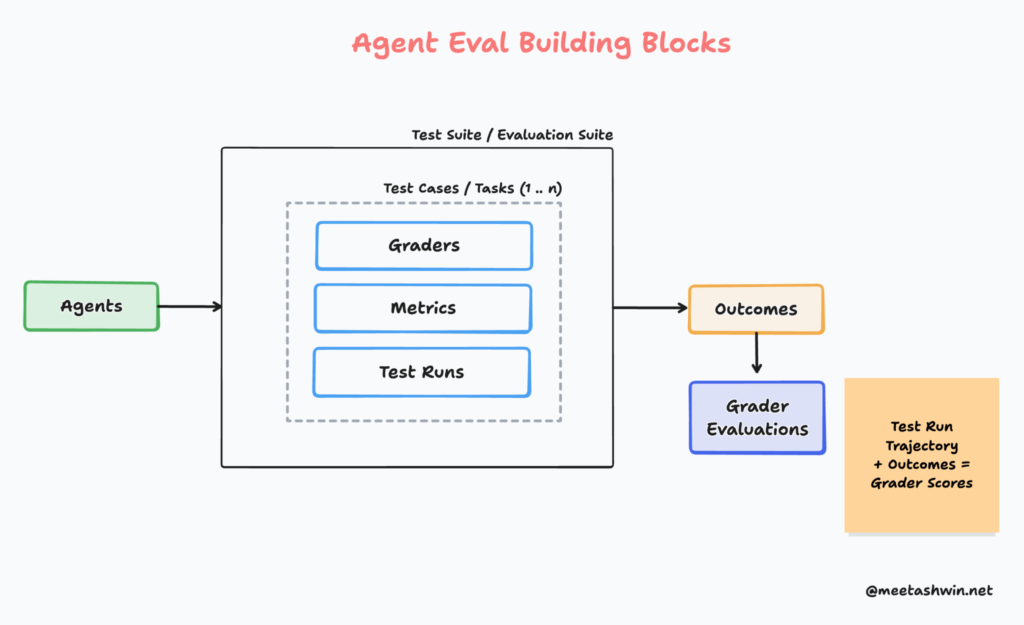
An Agent Evaluation system typically consists of these core building blocks:
Agents – The system under test that works toward specific objectives using tools and LLMs. While production systems often involve multiple agents, we treat them as a single entity for evaluation purposes.
Evaluation Suite – A comprehensive set of tasks or test cases that assess agents across various parameters and metrics. This is your complete testing framework.
Tasks – Individual test cases within the evaluation suite, each targeting specific agent capabilities or goals. Common metrics include task success rate, accuracy, latency, and cost per task.
Outcomes – The measurable outputs produced by agents during task execution. These represent what the agent actually accomplished and form the basis for evaluation—analogous to system test results in traditional software.
Graders – Automated or human evaluators that score outcomes against predefined rubrics, ground truth data, or reference outputs. Graders determine whether the agent succeeded and how well it performed.
While your evaluation system may include additional components depending on your specific testing needs, these building blocks provide a solid foundation for assessing any agentic system.
Eval-Driven Development (EDD) for Agentic Systems
Inspired by Test-Driven Development (TDD), which has improved software engineering for decades, Eval-Driven Development (EDD) places systematic evaluations at the core of the AI development lifecycle—not as an afterthought, but as the foundation.
Here are 4 core principles for a robust EDD approach:
1. Define success upfront – Establish clear, quantifiable metrics aligned with business goals before writing a single line of code. Define what “good” looks like: accuracy thresholds, acceptable latency, hallucination rates, task completion criteria.
2. Build comprehensive eval suites – Create test datasets covering common scenarios, edge cases, and adversarial examples. Your evals should stress-test your agents the way real-world usage will.
3. Evaluate continuously – Run your evaluation suite with every prompt change, model upgrade, or system modification. Treat evals like CI/CD—continuous measurement is the only way to catch regressions early and validate improvements.
4. Use multiple evaluation methods – Combine human grading for nuanced judgment, code-based assertions for objective metrics, and LLM-as-judge for scalable quality assessment. No single evaluation method captures the full picture.
Guided by these core principles, here’s a practical workflow for designing an evaluation system for your agentic application:
- Understand the business problem – Start with clarity on what success looks like for your stakeholders. What specific tasks must the agent accomplish? What quality bar must it meet? What failures are unacceptable?
- Assemble representative examples – Gather real data related to the problem: actual user queries, historical cases, common workflows, and known failure modes. Your eval dataset should mirror production reality.
- Build an end-to-end V0 system – Create a working prototype quickly, even if crude or incomplete. You need something functional to evaluate before you can improve it.
- Label data and build initial evals – Create ground truth labels for your examples and write your first evaluation metrics. Start simple: basic success/failure criteria and a handful of quality measures.
- Align evals to business metrics – This is critical. Map your technical metrics (accuracy, latency, tool usage) to actual business outcomes (customer satisfaction, cost savings, error reduction). If your evals don’t predict business value, they’re measuring the wrong things.
- Iterate on both system and evals – Improve your agent based on eval results, but also refine your evals as you discover what matters. Your evaluation framework should evolve alongside your system.
- Integrate into your development workflow – Embed evals into CI/CD, code reviews, and release processes. Make evaluation a continuous practice, not a pre-launch gate.
This creates a virtuous flywheel: better evals surface real problems, fixes improve performance, and improved performance validates your eval framework.
Agent Eval Frameworks in Practice
The ecosystem of agent evaluation tools is rapidly maturing. Here are four leading frameworks that can accelerate your evaluation efforts:
1. LangSmith (by LangChain)
LangSmith provides end-to-end observability and evaluation for LLM applications with excellent tracing of multi-step agent workflows. Its strength lies in visualizing complex agent reasoning chains and tight integration with the LangChain ecosystem, supporting human-in-the-loop evaluation, automated scoring, and A/B testing.
2. Braintrust
Braintrust is an enterprise-grade evaluation platform focused on production AI systems with strong CI/CD integration and powerful analytics. It excels at experiment tracking and comparing different agent architectures side-by-side, supporting code-based assertions, LLM-as-judge, and human review workflows.
3. Promptfoo
Promptfoo is an open-source, configuration-driven framework that emphasizes simplicity and flexibility for teams wanting full control. Its lightweight, local-first design and YAML-based test definitions make it ideal for rapid iteration and easy integration into CI/CD pipelines.
Key Takeaways
- Evaluation is non-negotiable. As AI agents become embedded in enterprise systems, a robust evaluation framework isn’t optional—it’s the foundation for reliability, trust, and measurable business impact.
- Adopt Eval-Driven Development. Just as TDD transformed software engineering, EDD must become your default approach for AI development. Build evaluations first, then build agents that pass them.
- Connect evals to business outcomes. Technical metrics matter only if they predict business value. Continuously align your evaluation framework with what stakeholders actually care about, and refine it as you gather more production data.
- Leverage the ecosystem. The evaluation tooling landscape is evolving rapidly. Use open-source and commercial frameworks to accelerate your evaluation maturity rather than building everything from scratch.
- The organizations that master agent evaluation today will be the ones deploying reliable, high-value AI systems tomorrow. Start building your evaluation practice now.
Disclaimer: The ideas, opinions, and recommendations expressed in this blog post are solely my own and do not reflect the views, policies, or positions of my employer.
Leave a Reply